
En un post anterior vimos como scrapear y extraer el texto de 40.000 documentos de la sección primera del boletín oficial argentino. En el de hoy, vamos a realizar un análisis de Natural Language Processing (NLP) en cada uno de esos documentos extraídos.
NLP
De todos las estudios que se pueden hacer con NLP vamos a hacer Named Entity Classification. Esto nos permitirá detectar verbos, sujetos, adjetivos, pronombres y signos de puntuación. Al mismo tiempo, y gracias a la herramienta que elegida, vamos a detectar personas, lugares geográficos, organizaciones y fechas. Todo esto lo vamos a hacer con una herramienta llamada freeling que se desarrolla en la Universitat Politècnica de Catalunya y cuenta con modelos para trabajar en el idioma Español. Destaco este punto porque la mayoría de las herramientas NLP trabajan casi exclusivamente en Inglés.
Empezamos instalando freeling con:
brew install freeling
o, en Ubuntu 14.04:
sudo apt-get update -yq
sudo apt-get install gdebi -yq
sudo apt-get install libboost-regex-dev libicu-dev zlib1g-dev \
libboost-system-dev libboost-program-options-dev \
libboost-thread-dev -yq
wget https://github.com/TALP-UPC/FreeLing/releases/download/4.0/freeling-4.0-trusty-amd64.deb
sudo gdebi -n freeling-4.0-trusty-amd64.deb
Para probarlo, necesitamos conocer la ubicación de los archivos de configuración:
- En osx:
/usr/local/Cellar/freeling/4.0/share/freeling/config - En Ubuntu:
/usr/share/freeling/config/
Luego podemos ejecutar:
$ export FREELINGSHARE=/usr/local/Cellar/freeling/4.0/share/freeling/
$ echo "Hola mundo" | analyzer -f /usr/local/Cellar/freeling/4.0/share/freeling/config/es.cfg
Hola hola I 1
mundo mundo NCMS000 1
Y, como en este caso queremos el módulo nec de named entity classification,
tendremos que correr:
$ echo "Abuelas encontró al nieto número 114" | analyze -f \
/usr/local/Cellar/freeling/4.0/share/freeling/config/es.cfg --nec --output json
Nuestro output será:
{
"id": "1",
"tokens": [
{
"id": "t1.1",
"form": "Abuelas",
"lemma": "abuelas",
"tag": "NP00SP0",
"ctag": "NP",
"pos": "noun",
"type": "proper",
"neclass": "person",
"nec": "PER"
},
{
"id": "t1.2",
"form": "encontr\u00f3",
"lemma": "encontrar",
"tag": "VMIS3S0",
"ctag": "VMI",
"pos": "verb",
"type": "main",
"mood": "indicative",
"tense": "past",
"person": "3",
"num": "singular"
},
{
"id": "t1.3",
"form": "a",
"lemma": "a",
"tag": "SP",
"ctag": "SP",
"pos": "adposition",
"type": "preposition"
},
{
"id": "t1.4",
"form": "el",
"lemma": "el",
"tag": "DA0MS0",
"ctag": "DA",
"pos": "determiner",
"type": "article",
"gen": "masculine",
"num": "singular"
},
{
"id": "t1.5",
"form": "nieto",
"lemma": "nieto",
"tag": "NCMS000",
"ctag": "NC",
"pos": "noun",
"type": "common",
"gen": "masculine",
"num": "singular"
},
{
"id": "t1.6",
"form": "n\u00famero",
"lemma": "n\u00famero",
"tag": "NCMS000",
"ctag": "NC",
"pos": "noun",
"type": "common",
"gen": "masculine",
"num": "singular"
},
{
"id": "t1.7",
"form": "114",
"lemma": "114",
"tag": "Z",
"ctag": "Z",
"pos": "number"
}
]
}
En este caso el resultado está en formato JSON y tiene un error ya que Abuelas es una organización y no una persona. Claramente el model necesita un poco de entrenamiento en DDHH argentinos. El entrenamiento será un cuento para otro día.
El código será escrito en python, y por ende necesitamos instalar un wrapper
para freeling llamado pyfreeling.
Su uso es muy similar al uso de analyze, la herramienta de línea de comandos
que viene con freeling.
Map reduce
Este paso es opcional
El análisis nec consume mucha memoria, procesador y, por supuesto, mucho
tiempo. Una forma simple de acelerar el proceso es usar más de un
nodo o computadora. Aquí vamos a usar un map-reduce manual para dividir
el proceso en 2 nodos: uno en DigitalOcean con 32Gb de ram y 12 CPUs y
el otro, una laptop con 16Gb de ram y un procesador i7 de 3.1GHz.
El archivo con los 40.000 documentos pesa 325M y su estructura es la siguiente:
- Un JSON por línea.
- Cada JSON es un documento con título, metadata y contenido en HTML.
Cómo tenemos un JSON por línea, podemos dividir el archivo por número de líneas:
split -n 20000 output.dat
Dask nos permite paralelizar en multiples nodos, pero no vamos a usar ese feature en este post. El propósito es usar 2 nodos,
Ese comando nos va a dar 2 archivos con 20.000 documentos para usar en cada nodo.
Empezando con dask
Una vez copiado el archivo en cualquiera de los nodos, podemos leer su
contenido con read_text y generar un objeto bag de Dask. También
vamos a encadenar algunas funciones para parsear el JSON, extraer el texto
del html, eliminar documentos nulos, etc:
import ujson
import dask.bag as db
from bs4 import BeautifulSoup
def extract(blob):
return blob['dataList']
def remove_empty(data_list):
return data_list
def valid_columns(data):
return {
'detalleNorma': data['detalleNorma'],
'idTramite': data['idTramite']
}
def extract_text(data):
try:
return {
'idTramite': data['idTramite'],
'parsedText': BeautifulSoup(data['detalleNorma'], "html.parser").\
getText().strip()
}
except:
return None
def remove_nones(data):
return data is not None
bag = db.read_text("file_1.dat", blocksize=100000000)
df = bag.map(ujson.loads).map(extract).filter(remove_empty).\
map(valid_columns).map(extract_text).filter(remove_nones)
Vamos a usar un blocksize de 100.000.000 que Dask organizará en
4 workers similares. Para generar esa
gráfica usamos: from dask.dot import dot_graph; dot_graph(df.dask).
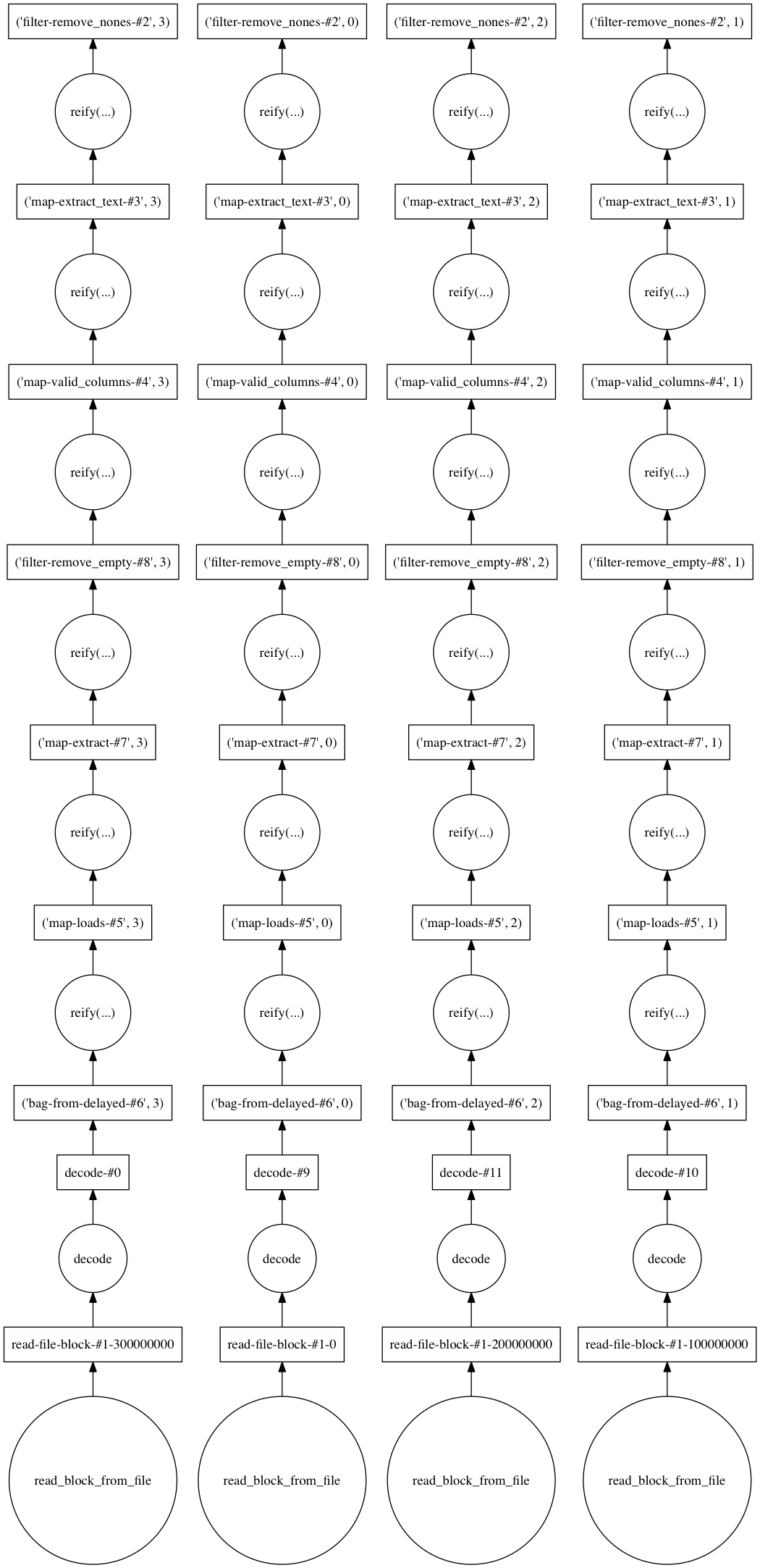{kind=link}
Análisis de entidades
Una vez que tenemos un bag de Dask con los datos y los workers listos podemos llamar a freeling con:
from pyfreeling import Analyzer
def tokenize(data):
try:
analyzer = Analyzer(config='/usr/share/freeling/config/es-ar.cfg')
tokens = []
xml_root = analyzer.run(data['parsedText'].encode('utf-8'), 'nec')
for element in xml_root.iter():
if element.tag == 'token':
tokens.append(dict(element.attrib))
except Exception as e:
print(data['idTramite'])
print(e)
return {'idTramite': data['idTramite'], 'tokens': tokens}
tokens = df.map(tokenize)
Y luego bajamos todo a disco:
tokens.map(ujson.dumps).to_textfiles('{}.*.dat'.format(filename))
Esta tarea toma varias horas y como resultado obtendremos algunos archivos llamados: file1.dat.0.dat, file1.dat.1.dat, etc. Y su contenido será similiar a:
{
"idTramite": "100000",
"tokens": [
{
"ctag": "NP",
"form": "MINISTERIO_DE_TRABAJO",
"neclass": "organization",
"pos": "noun",
"nec": "ORG",
"lemma": "ministerio_de_trabajo",
"tag": "NP00O00",
"type": "proper",
"id": "t1.1"
},
{
"ctag": "Fc",
"form": ",",
"pos": "punctuation",
"lemma": ",",
"tag": "Fc",
"type": "comma",
"id": "t1.2"
},
...
]
}
Nota: La estructura con la que organizamos los tokens es muy ineficiente. No se es tabular y por lo tanto debe ser convertida en un último paso. Este último paso se podría haber omitido con una mejor estructura.
import ujson
from dask import bag
def tabulate(data):
tokens = []
for token in data['tokens']:
token['idTramite'] = data['idTramite']
tokens.append(token)
return tokens
b = bag.read_text('file_1.dat.*.dat').map(ujson.loads).\
map(tabulate).concat()
b.map(ujson.dumps).to_textfiles('tabulated.*.dat')
En próximos posts haremos análisis de los 33.276.028 datos obtenidos. Y si te queres adelantar, los podes bajar aquí.
Nota: Publiqué un notebook con el código de ejemplo usado aquí. Lamentablemente no se puede ejecutar pues Binder no tiene freeling instalado. Link al notebook.