
Analizando el Boletín Oficial
El Boletín Oficial, según Wikipedia, es “el medio de comunicación escrito que el Estado argentino utiliza para publicar sus normas jurídicas (tales como leyes, decretos y reglamentos) y otros actos de naturaleza pública, tanto del poder legislativo como del ejecutivo y el judicial”. Se compone de cuatro secciones que se enfocan en normas jurídicas, sociedades, contrataciones y dominios de internet respectivamente. Su sitio web es www.boletinoficial.gob.ar y por suerte es muy fácil de scrapear.
En este primer blogpost me voy a enfocar en la Primera Sección que incluye leyes, decretos, resoluciones y disposiciones emanadas de organismos públicos de los tres poderes del Estado.
Scraping the bad way
Si te interesa bajar la primera sección, hace click aquí.
Hace unos años atras escribí un post sobre consejos a la hora de hacer scraping. Hoy NO voy a respetar ninguno de esos consejos pues no tengo interes en reproducir este scraping ni nada por el estilo.
El primer paso consiste en visitar la página del Boletín Oficial y analizar qué tipos de llamadas se hacen desde el sitio.
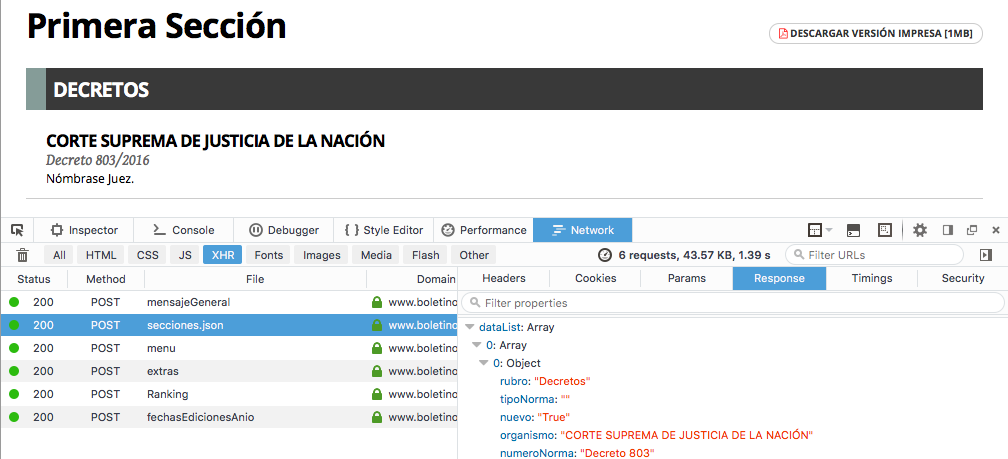
Podemos distinguir, fácilmente, una llamada del tipo POST a secciones.json que
devuelve un arreglo con los elementos de la Primera Sección para la fecha
enviada como parámetro de la llamada.
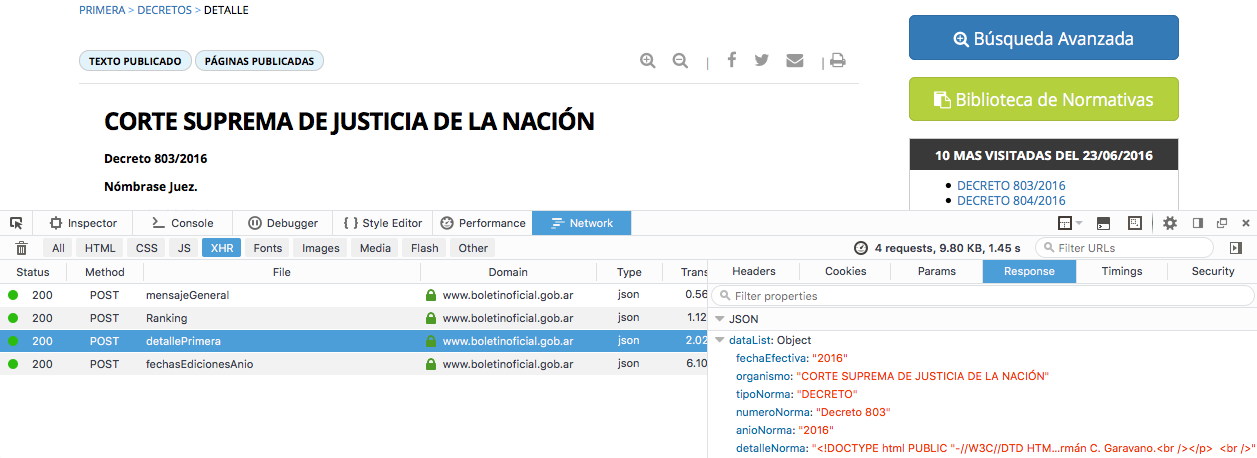
Luego, hacemos click en caulquier decreto o resolución de la página. Una vez
que la página se actualice veremos una llamada a detallePrimera, si la
inspeccionamos veremos entre otras cosas el contenido del Decreto,
la fecha de publicación, el nombre del archivo con el que fue publicado
y su contenido. Esta va a ser la URL que vamos a probar con cURL:
$ curl --silent -q --data "numeroTramite=147002" \
https://www.boletinoficial.gob.ar/norma/detallePrimera
Y como resultado tendremos:
{
"dataList": {
"fechaEfectiva": "2016",
"organismo": "CORTE SUPREMA DE\u00a0JUSTICIA DE\u00a0LA\u00a0NACI\u00d3N\r\n",
"tipoNorma": "DECRETO",
"numeroNorma": "Decreto 803",
"anioNorma": "2016",
"detalleNorma": "HTML CONTENT",
"idTramite": "147002",
"cantidadVisitas": 2135,
"cantidadVisitasHoy": 2135,
"fechaDeHoy": "20160623",
"paginaDesde": "1",
"paginaHasta": "1",
"cantidadPaginasAfectadas": null,
"cantidadPaginasAfectadasPor": null,
"cantidadPaginasNormaFechaEfectiva": null,
"cantidadPaginasVisitadas": null,
"cantidadPaginasAnoexos": 0,
"anexosNorma": [
],
"normasAfectadas": [
],
"normasAfectadasPor": [
],
"fechasEfectivaNorma": [
],
"normasVisitadas": [
],
"idRubro": "24",
"descRubro": "Decretos",
"archivoPDF": "2016062301N.pdf",
"fechaPublicacion": "20160623",
"suplemento": false,
"idTipoNorma": "2"
},
"id": "hcuvPSIvRwwrf5FU52+Ovi1bLS1JVi1bLUKbcb5YiYrnLAFxN7RJbCs=",
"codigoError": 0,
"mensajeError": ""
}
Eso es exactamente lo que queremos! Ahora vamos a usar seq y parallel
para bajar los archivos con:
seq 100000 1 140000 | parallel -j10 \
"curl --silent -q --data "numeroTramite={}" \
https://www.boletinoficial.gob.ar/norma/detallePrimera --output {}.json"
Esto nos va a generar 40000 archivos JSON que voy a unir con:
for f in *.json; do (cat "${f}"; echo) >> output.dat; done
Así logramos un único (output.dat) archivo para empezar a jugar.
Cargar los datos
Para cargar los datos usamos Dask. Básicamente,
leemos el archivo línea por línea, parseamos con ujson y si el resultado
tiene un elemento llamada detalleNorma asumimos que es un documento válido. A
cada documento le extraemos el exto con
BeautifulSoup4.
Pasamos todo el texto a minúsculas, filtramos los componentes que no son
palabras, las denominadas stop words (palabras que no me dan valor) y por último
contamos la aparición de cada palabra:
import re
import ujson
import dask.bag as db
from bs4 import BeautifulSoup
bag = db.read_text("output.dat")
is_word = lambda x: re.search("^[a-zA-ZáéíóúüñÁÉÍÓÚÜÑ]+$", x) is not None
not_is_stopword = lambda x: x not in nltk.corpus.stopwords.words('spanish')
def extract(blob):
if blob['dataList']:
html = blob['dataList'].get('detalleNorma', '')
if html is not None:
return BeautifulSoup(html, "html.parser").getText().lower().strip().split()
return []
res = bag.map(ujson.loads).map(extract).concat().\
filter(is_word).filter(not_is_stopword).\
frequencies().compute()
Una vez que tenemos la frecuencia de cada palabra en todos los documentos de la Primera Sección ordeno y mostramos las 10 palabras más frecuentes:
sort = sorted(res, key=lambda x: x[1], reverse=True)
sort[0:10]
Top 10 de palabras en la sección primera
| Palabra | Frecuencia |
|-----------|------------|
| dni | 213703 |
| Nº | 188174|
| nacional | 184061|
| calibre | 133918|
| ley | 114651|
| decreto | 112959|
| presente | 112024|
| ministerio| 111594|
| fecha | 96887|
| plg | 75974|
Sólo a modo de prueba, hay publicado un notebook con algunos documentos y el código de este post aquí.
Nota: Tengo pensado jugar un poco más con estos datos en futuros posts.